robot.txt
2022/10/10 20:04:00
User-Agentを一般のコンピュータに偽装してクロールする輩が出てきたので、robot.txtで有力な検索エンジン以外を除外。
「これも入れるべきだ」みたいなのがあればコメント求む。
User-agent: *
Disallow: /
User-agent: Googlebot
User-agent: bingbot
User-agent: DuckDuckBot
Allow: /
User-Agentを一般のコンピュータに偽装してクロールする輩が来て気になったのだが、私が動かしてるデライトをクロールするクローラ(dlt_crawler.js)のUser-Agentは何になってるんだろう。Node.jsでgotを使っているので、gotになっているはず……?
Node.jsでgotを使った際のUser-Agentはgot (https://github.com/sindresorhus/got)となっていた。実際にサーバにgotを通してアクセスし、アクセスログを確認した
gotのレポジトリでuser-agentと検索してみると、headersという引数でUser-Agentを設定できそうだ。
headers: {
'user-agent': undefined
}
とりあえず、dlt_crawler.js by t_w(https://towasys.com/)としておこう。こちらUser-Agentが反映されていることをサーバにアクセスして確認済みだ。
コードは以下のようになった。
response = await got(url, {
headers: {
'user-agent': 'dlt_crawler.js by t_w(https://towasys.com/)'
}
});
というかrobot.txtをガン無視しているのでお行儀が悪い気がしてきた。さらっと調べたらデライトにrobot.txtは設定されていないっぽい……?じゃあいいか……いいのか?
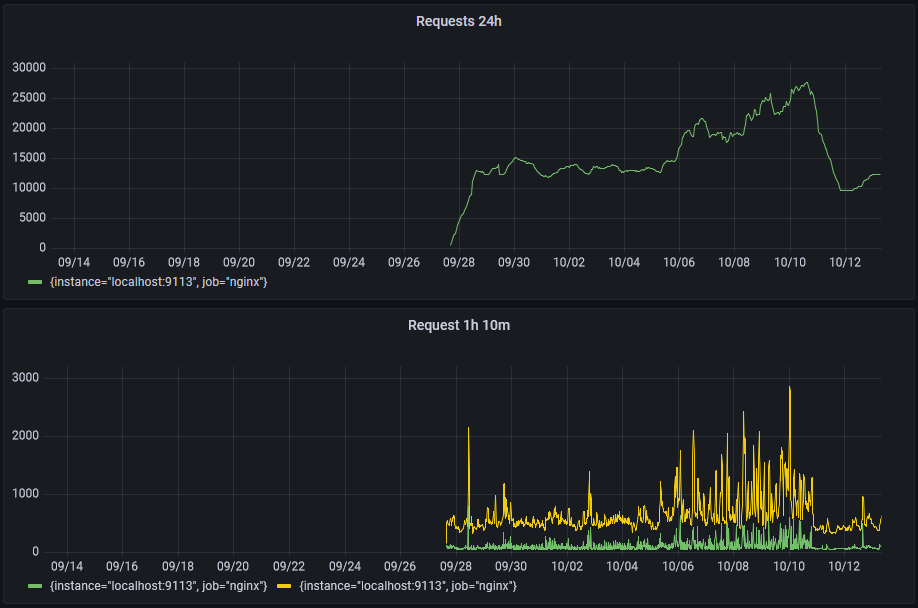
なんか『t_wの輪郭』のアクセス数が急増している。アクセス数が2倍ぐらい。DoSか?
nginxのログをみる感じでは、MJ12bot(MJ12bot/v1.4.8) と DotBot(DotBot/1.2) が結構アクセスしてきている。
SemrushBotと同様に、robot.txtで拒否して終わり!明日になったら結果を見る。
User-agent: SemrushBot
User-agent: dotbot
User-agent: MJ12bot
Disallow: /
アクセス数が激減していることを確認した。nginxのログでも、MJ12bot と DotBotのアクセスが無くなっている。