実現性検証
2020/9/20 13:51:00
http://54.250.48.30:8080/
Elastic IPを設定した
気が向いたらドメインを取得して設定する
デライト外部検索通類をAWSへデプロイした。↓のリンクから利用できる
http://ec2-52-193-108-6.ap-northeast-1.compute.amazonaws.com:8080/
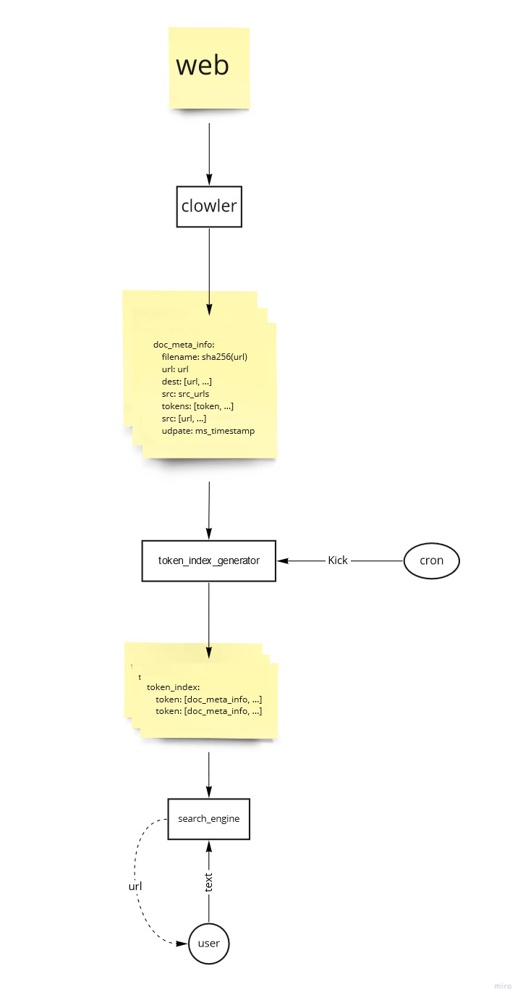
デライトクローラが取得した1万9千の輪郭から検索できる
コマンドラインからデライトを検索できるところまでは来た
検索が一瞬で終わる
連想配列から単語をキーとしてURLを取ってくるだけなので早い
ただ、検索結果にURLしか表示されない
デライトクローラをメタデータだけでなくページ内の内容も保存するように改変する
デライトクローラの再開時に、ファイルに保存したメタデータを読み込むようにした
これでクロールを途中から再開できる
現時点では全メタデータを読み込む
メタデータの増加に合わせて、処理時間と消費メモリーが線形に増加する想定だ
こいつが膨大なデータを集めるまえに、よりかしこい処理方式を実装しなければならない