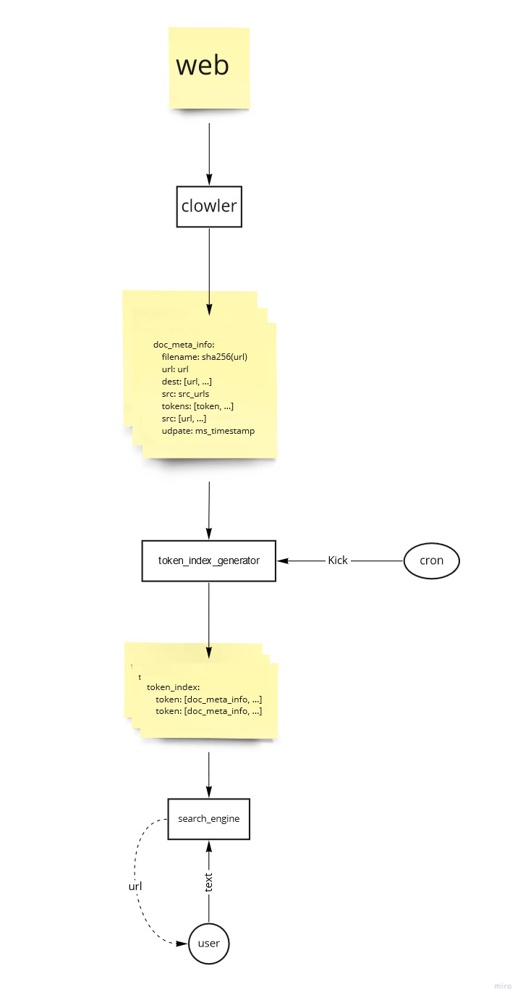
クローラー
2021/11/28 13:59:00
import fs from "fs";
import * as R from "ramda";
import { Window } from "happy-dom";
import { urls } from "./urls";
const window = new Window();
const dom_parser = new window.DOMParser();
const queue = new Map<string, { got: boolean }>(
urls.map((url) => [url, { got: false }])
);
// filesのファイル一覧
const file_names = fs.readdirSync("./files");
const file_names_base64 = file_names.map((file_name) => {
const [url_base64, file_ext] = file_name.split(".");
return url_base64;
});
const got_url_base64_set = new Set<string>(file_names_base64);
console.info({ got_url_base64_set });
for (;;) {
try {
const urls_for_scraping_groupby = R.groupBy((url) =>
url.includes("pdf") ? "pdf" : "else"
)([...queue].filter(([url, { got }]) => !got).map(([url, { got }]) => url));
const urls_for_scraping = [
...(urls_for_scraping_groupby.pdf ?? []),
...(urls_for_scraping_groupby.else ?? []),
];
if (urls_for_scraping.length === 0) {
break;
}
const url = urls_for_scraping[0];
console.info({ url });
const url_base64 = Buffer.from(url).toString("base64");
if (got_url_base64_set.has(url_base64)) {
queue.set(url, { got: true });
continue;
}
queue.set(url, { got: true });
await sleep(2000);
const fetch_result = await fetch(url);
const file_type = fetch_result.headers.get("content-type");
if (file_type === null) {
console.warn("file type is null");
continue;
}
// 拡張子
const file_ext = file_type.split("/")[1];
// urlをbase64にしてファイル名にする
const file_name = `./files/${url_base64}.${file_ext}`;
if (file_ext == "html") {
const file_text = await fetch_result.text();
const urls_next = await links_get_from_html_text(file_text);
// Mapに追加
urls_next
.filter((url) => !queue.has(url) && url.includes("go.jp"))
.forEach((url) => {
queue.set(url, { got: false });
});
if (!file_text) {
console.warn("file is null");
continue;
}
await fs.writeFile(file_name, file_text, () => {});
}
if (file_ext == "pdf") {
const file_name = `./files/${crypto.randomUUID()}.${file_ext}`;
const array_buffer = await fetch_result.arrayBuffer();
await fs.writeFile(file_name, Buffer.from(array_buffer), () => {});
}
} catch (error) {
console.error("catch", error);
}
}
async function sleep(ms: number) {
return new Promise((resolve) => setTimeout(resolve, ms));
}
async function links_get_from_html_text(text: string) {
const dom = dom_parser.parseFromString(text, "text/html");
const a_elems = dom.querySelectorAll(`a`);
const urls = a_elems
.map((a: any) => a.href)
.filter((href) => href?.includes("go.jp"));
return urls;
}
=15.718837606837608[KB]
=0.015350427350427352[MB]
=8.98 / 585 [MB]
関連するURLのリストを持つと、やはり容量が大きくなる
数だけ持つべきかもしれない
ページランクを無視するならURLは残さなくてもいい
= 156.6405989165999[TB]
= 168191562393.1624[KB]
= 15.718837606837608 * 10700000000 [KB]
= ページメタ情報の容量 * クローラで得られるページ数
8:30に出社した。7.5時間労働なので、17:00に退社できる。
17:30ごろに退社した。30分の残業。
鍋から冷たいままお箸で入れたのが良くなかったのだろう。角煮に火を入れた後にインテグレーションして密封すればまだマシだったはずだ。まだ気温も暖かいので温度も良くなかった。やはり冷凍が最強かもしれない。
大元の鍋に入っている角煮は無事だろうか。冷蔵庫の中なら大丈夫と思いたい。早く消費したい。
こういうことがあるから作り置きは避けたい。衛生においても一個流しは最強である。
仕方がないのでセブンイレブンで一風堂監修のラーメンを買って食べた。なんか一蘭のラーメンを食べたくなった。
家に帰って本元の鍋の角煮を見たところ、こちらも赤いものが付着していた。捨てた。調味料に見えなくもないのだけど、醤油と砂糖以外入れた覚えがないのでカビだと思う。もったいないが、健康には変えられない。体調を崩して寝こめば時給換算においても損だ。
knownetの検索のデモンストレーションのために、金商法の条文でも入れてやるかと思い、少し見て見てみたら、凄まじい文量で尻込みした。コレを入れようとするとまる一日かかってしまいそうだ。辞めとこうとなった。
投稿同士の多対多の紐付け・表題の完全一致検索・検索語の分かち書き だけで、擬似的な全文検索ができてしまった。わけがわからん。投稿そのものをインデックスとして使える特性によって全文検索が実現できている。ちゃんと全文検索を作ろうとすると、普通ならインデックスを作り込まないといけない。
類似度継承によって、検索精度も他と比較にならない高さになっている。意図した検索結果が得られている。検索をより良くするための案である、応向分離もまだある。もしかしたならば、クローラーと組み合わせたならば、何もかもがうまく行ったならば、Google検索を超えられるのではないだろうか。
覚えるということは飽きるということの第一歩であろうから、次々に関心の対象が進んでいくことになると思うが、そうしていったときに何かに行きついたりするだろうか。
クローラーとして見れば、興味の対象がなくなって停止してしまいそうだが、停止するほど世界は狭くないはず。
本文がある輪郭の抽出に当たって、クローラーというかWebスクレイピングを組めばいいんだろうけど、継続的に使える仕組みにするのは面倒だしデライトに負荷がかかりかねないので微妙だ。
1ページあたり10輪郭を取得できるので、10秒ごとに取りに行ったとすると1万輪郭は10000/10 = 1000秒 ≒ 16分ぐらいかかる計算になる。
エクスポート機能が実装されるのを待ったほうがいいかもしれない。
それか、日々デライトを見て回っていて気になった奴だけ手動でnoteに転載していくか
デライトで読めばいいじゃんとか思ってしまうが、まあデライト自身は共有しにくさがあるし意味はあるだろう。万が一デライトが使えなくなった時のバックアップにもなる。
デライト外部検索通類をAWSへデプロイした。↓のリンクから利用できる
http://ec2-52-193-108-6.ap-northeast-1.compute.amazonaws.com:8080/
デライトクローラが取得した1万9千の輪郭から検索できる
コマンドラインからデライトを検索できるところまでは来た
検索が一瞬で終わる
連想配列から単語をキーとしてURLを取ってくるだけなので早い
ただ、検索結果にURLしか表示されない
デライトクローラをメタデータだけでなくページ内の内容も保存するように改変する
デライトクローラの再開時に、ファイルに保存したメタデータを読み込むようにした
これでクロールを途中から再開できる
現時点では全メタデータを読み込む
メタデータの増加に合わせて、処理時間と消費メモリーが線形に増加する想定だ
こいつが膨大なデータを集めるまえに、よりかしこい処理方式を実装しなければならない
検索エンジンの作り方についてのスライド
https://speakerdeck.com/ryook/the-first-step-self-made-full-text-search
🟩メタデータを圧縮する
🟩URLを無くす
検索結果が、自分にとって良いものになりやすいのではないか
日本人であれば、日本語のページが重点的にクロールされる
技術者であれば、技術サイトが重点的にクロールされる
閲覧履歴からのホップ数でページランクをつけてもいいかもしれない
広告がついているページのページランクを落とす
収益を無視した個人サイトがたくさん出てくるのではないか
ブラウザの閲覧履歴を元にウェブをクロールする
検索実施時にクロール結果から検索する
クローラーはブラウザエクステンションで常駐させる
WSL2を動かしっぱなしにするとメモリーを食いつぶすらしい
クローラーのプログラムは関係なかった
クローラーのメモリー消費を試算したら、高々400MB程度で済む