検索エンジン
2021/3/24 22:30:00
世の検索エンジンがベクトル検索を使ってるせいか知らんけども補正が強すぎる。
Xの方は字で検索してくれてる感じがあって「デススタバ」とか検索した時にしっくり来る結果が出てくる。
1週間ほどスマホのデフォルトの検索エンジンをGoogleからBingに変更してみているが、思ったような検索結果とならなくて辛い。
アメリカと戦うと言った意味では、まともな国産検索エンジンがないのが口惜しい。陰謀論みたいになってしまうが、アメリカがその気になればGoogle検索にくだらない記事を混入させるといったこともできてしまう。意図的じゃなくとも、検索結果にかける熱量もとい手間の量がそもそも違うだろう。ただ、現時点の話をすれば、Google検索は日本語を重要視しているらしい。
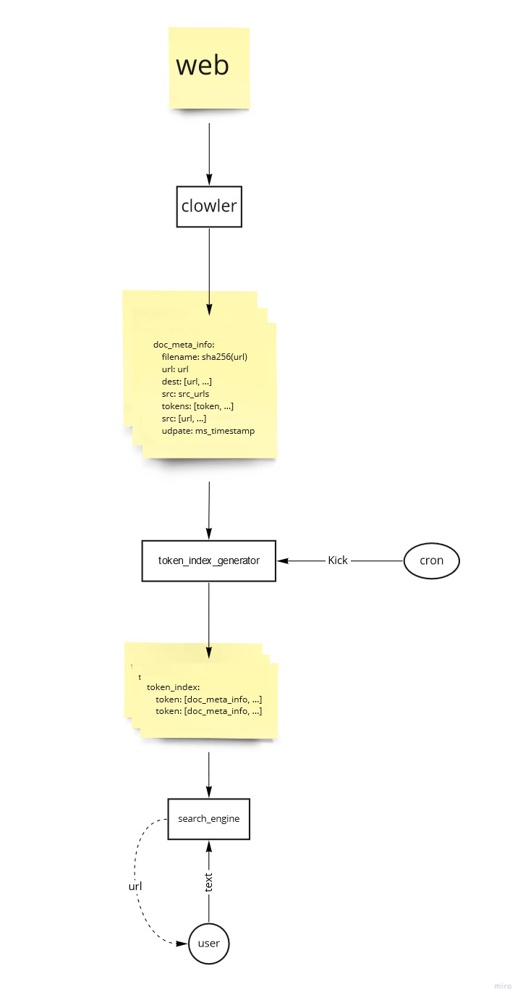
そう言った意味では、ローカルのPCでクローラを回してオープンソースの検索エンジンを動かすというのは悪いアイデアじゃない。今流行りのプライバシーにも完璧に対応できる。ただ、インターネットの圧倒的な物量にはインデックスであってもローカルのPCには入りきらないということが絶望的に欠点だった。
今から追い上げるのは難しいにしても、いつでも作れるような地固めはできないものだろうか。
ある。
でも、コンテンツを一つのサービスに閉じ込めて、それはインターネットのように継続できるのだろうか。
儲かり続けるなら継続できるだろうか。
サービスは消えるがプロトコルは残る。メールサービスは消えてもメール(SMTP)は消えない
検索エンジンとコンテンツ作成環境は両輪
最高のアイデアというのは不可能のすぐ手前にある。これがそもそも可能なのかどうか知らないが、可能かもしれない兆候はある。新しい検索エンジンを作るというのはGoogleと戦うことを意味するが、Googleの要塞にもひび割れができていることに最近気づいた。
✓右クリックメニューから検索可能にする
✓ショートカットキー設定
✓起動時読み込みの高速化
✓ポップアップ作成
✓文字列入力欄の作成
✓メモリにページを保存せず、ストレージに保存する
✖indexedDBのラッパーを、localforageからjsStoreに乗り換える
✖検索エンジンに設定できるようにする
レコメンデーションシステムとしてのWeb Prowlerはあまり満足のいくものにはならなかった。方針転換して検索エンジンにしてしまうのも良いかもしれない。そうすればChrome addon化も可能になり利用者数増大を狙うこともできる。
複数の検索エンジンのラッパー
検索エンジン
ブラウザ拡張機能から検索エンジンを設定できる
っぽい
https://mocobeta.medium.com/動的転置インデックス-増分インデックスの保守とインデックス更新-検索性能のトレードオフ-598337dbf3a3
検索エンジンの転置インデックスがでかくなりすぎてメモリーに乗っからなくなった時に、どういう対処があるかについて書かれてる
『情報検索 :検索エンジンの実装と評価』 13200円
個人で買うには勇気がいる
何とか理由をつけて会社に買わせたい
デライト外部検索通類をAWSへデプロイした。↓のリンクから利用できる
http://ec2-52-193-108-6.ap-northeast-1.compute.amazonaws.com:8080/
デライトクローラが取得した1万9千の輪郭から検索できる
コマンドラインからデライトを検索できるところまでは来た
検索が一瞬で終わる
連想配列から単語をキーとしてURLを取ってくるだけなので早い
ただ、検索結果にURLしか表示されない
デライトクローラをメタデータだけでなくページ内の内容も保存するように改変する
デライトクローラの再開時に、ファイルに保存したメタデータを読み込むようにした
これでクロールを途中から再開できる
現時点では全メタデータを読み込む
メタデータの増加に合わせて、処理時間と消費メモリーが線形に増加する想定だ
こいつが膨大なデータを集めるまえに、よりかしこい処理方式を実装しなければならない