puppeteer
2020/9/20 13:56:00
- ウェブアプリ試験の自動化
- ウェブアプリの自動操作(RPAみたいなもの)
- ウェブから情報を自動収集
≪Headless Chrome Node.js API≫
https://github.com/puppeteer/puppeteer
≪Headless Chrome Node.js API≫
https://github.com/puppeteer/puppeteer
CloudWatch SyntheticsがPuppeteerでサービスの監視ができて良さそうだなってみてたんだけど、5分毎の処理で月額1万円こえるみたいでしんどい。
サーバー側で304(Not Modified)を解決するキャッシュプログラムの仮称
Githubレポジトリ: https://github.com/towasys/octpepper
キャッシュの実装が面倒(な予感)なので、puppeteerを使って、Chromiumのキャッシュ機構に乗っける(ことができるといいなぁ)。
Chromiumじゃなくても良さそうになってきた。
JavaScriptを書けば書くほど落とし穴を自分で掘ってる感じがする
Typescriptに変えよう🥺🥺🥺
Typescript勉強するか~~~~~~
puppeteerによる自動テストもやってみてるけど、早すぎた感
ライブラリに渡す引数に何渡せばいいかわかるし、タイポも減らせるし、バグを圧倒的に減らせたからオヌヌメ・・・!
拡張子をjsからtsに変えたら、至る所が真っ赤になってわろてる
お、tsへの移行が完了した。
300行のJavaScriptだったけど、TypeScriptへの移行に1.5時間かかった。
これから効率が良くなるので、これから取り戻せるはず。
Puppeteerのようなブラウザ自動操作ツールをサーバ上で動かせばScrapboxへの書き込みを自動化できる。ただし、自分だけが使えるサービスになる。一旦はそれでいいかな。
公開されたサービスにして、広く利用してもらいたい気持ちがある。
https://twitter.com/tuppye/status/1323533538042413056
デライト外部検索通類をAWSへデプロイした。↓のリンクから利用できる
http://ec2-52-193-108-6.ap-northeast-1.compute.amazonaws.com:8080/
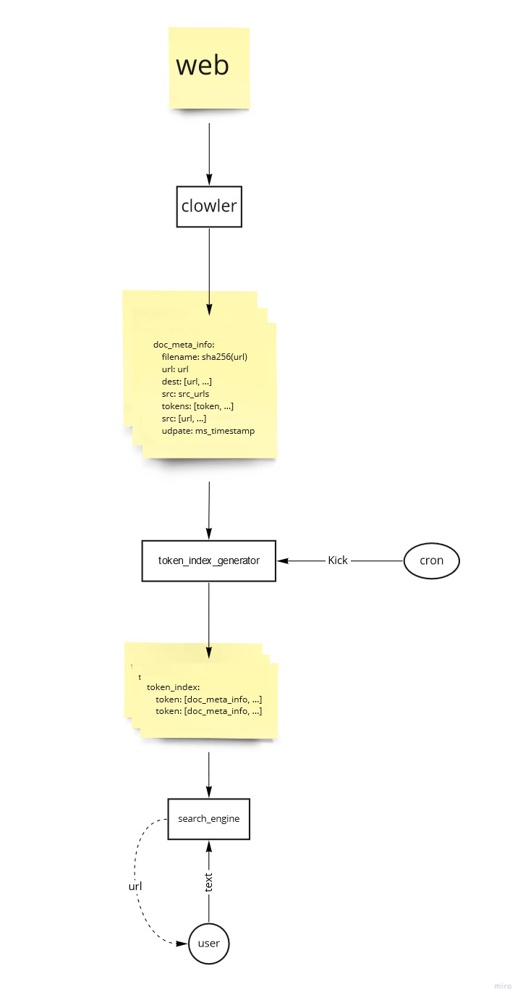
デライトクローラが取得した1万9千の輪郭から検索できる
コマンドラインからデライトを検索できるところまでは来た
検索が一瞬で終わる
連想配列から単語をキーとしてURLを取ってくるだけなので早い
ただ、検索結果にURLしか表示されない
デライトクローラをメタデータだけでなくページ内の内容も保存するように改変する
デライトクローラの再開時に、ファイルに保存したメタデータを読み込むようにした
これでクロールを途中から再開できる
現時点では全メタデータを読み込む
メタデータの増加に合わせて、処理時間と消費メモリーが線形に増加する想定だ
こいつが膨大なデータを集めるまえに、よりかしこい処理方式を実装しなければならない
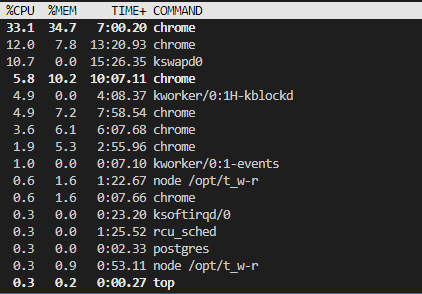
dockerだとpuppeteerがいい感じに動いている
プログラムの作りが悪いので、メモリー食いつぶしているが、この状態でも動き続けている

突然動かなくなる
puppeteerと相性が悪いらしい
Dockerなり、WSL2なりでWindowsと隔離して動かしたほうが良さそうだ