デライトでクローラーを回す
2020/9/21 23:17:00
=15.718837606837608[KB]
=0.015350427350427352[MB]
=8.98 / 585 [MB]
関連するURLのリストを持つと、やはり容量が大きくなる
数だけ持つべきかもしれない
ページランクを無視するならURLは残さなくてもいい
= 156.6405989165999[TB]
= 168191562393.1624[KB]
= 15.718837606837608 * 10700000000 [KB]
= ページメタ情報の容量 * クローラで得られるページ数
デライト外部検索通類をAWSへデプロイした。↓のリンクから利用できる
http://ec2-52-193-108-6.ap-northeast-1.compute.amazonaws.com:8080/
デライトクローラが取得した1万9千の輪郭から検索できる
コマンドラインからデライトを検索できるところまでは来た
検索が一瞬で終わる
連想配列から単語をキーとしてURLを取ってくるだけなので早い
ただ、検索結果にURLしか表示されない
デライトクローラをメタデータだけでなくページ内の内容も保存するように改変する
デライトクローラの再開時に、ファイルに保存したメタデータを読み込むようにした
これでクロールを途中から再開できる
現時点では全メタデータを読み込む
メタデータの増加に合わせて、処理時間と消費メモリーが線形に増加する想定だ
こいつが膨大なデータを集めるまえに、よりかしこい処理方式を実装しなければならない
『大規模なデータをJSON.stringifyとBlobを使って保存しようとしたら,ブラウザがエラーを出すときの対処法』
https://qiita.com/Toyoharu-Nishikawa/items/dfb187cf6eb4ba743995
JSON.stringifyに大きいオブジェクトを渡すと、JSONに変換してくれないのでD言語に避難
副次的効果として高速化も期待できる
D言語でも同じ問題が起きないことを祈る
D言語でもダメなら、次はPythonを試す
Node.jsでは、{}が出力される
検索エンジンの作り方についてのスライド
https://speakerdeck.com/ryook/the-first-step-self-made-full-text-search
🟩メタデータを圧縮する
🟩URLを無くす
ブラウザの閲覧履歴を元にウェブをクロールする
検索実施時にクロール結果から検索する
クローラーはブラウザエクステンションで常駐させる
376ファイルで、10MB程度になった
想定よりも容量が大きい
2,600,000ファイルなら、69148MB=69GB
生のHTMLを保存しているから大きいのだろう
クローラを野に放つなら、生のHTMLではなくインデックスを保存したほうが良さそうだ
ひとまずネットワーク容量と、保存容量の限界まで回してみる
→プロバイダから怒られるかもと思ったが、ゲームのダウンロードに比べれば、かわいい物だな
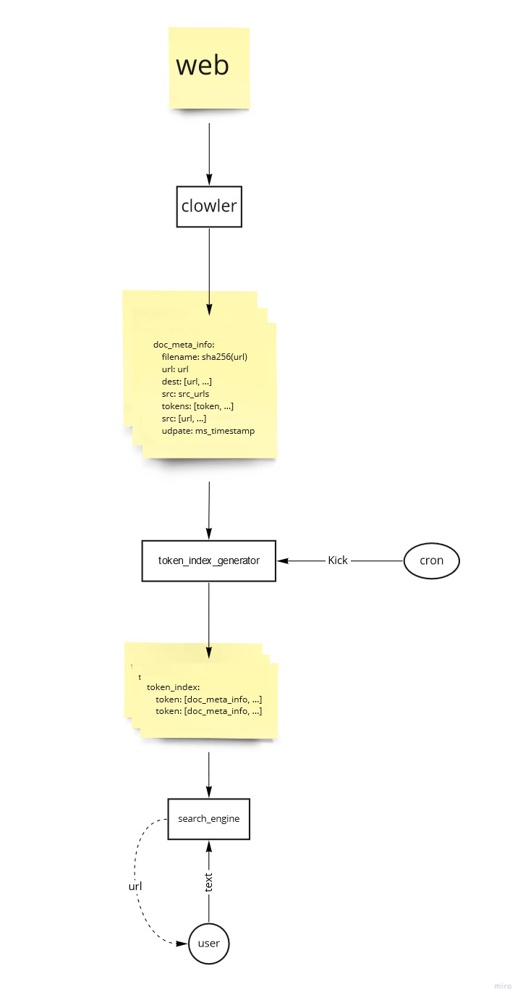
doc_meta_info:
filename: ページのURLのsha256
dest: ページが持つURLのリスト
src: ページを指し示すURLのリスト
tokens: ページ内の単語
udpate: メタ情報の作成時刻(timestamp[ms])
WSL2を動かしっぱなしにするとメモリーを食いつぶすらしい
クローラーのプログラムは関係なかった
クローラーのメモリー消費を試算したら、高々400MB程度で済む
dockerだとpuppeteerがいい感じに動いている
プログラムの作りが悪いので、メモリー食いつぶしているが、この状態でも動き続けている

突然動かなくなる
puppeteerと相性が悪いらしい
Dockerなり、WSL2なりでWindowsと隔離して動かしたほうが良さそうだ
エラーコード:
DESKTOP-A0TO8ET:/mnt/d/google drive/work/Delite-Clowler$ node main.js
(node:14699) UnhandledPromiseRejectionWarning: Error: Failed to launch the browser process! spawn /mnt/d/google drive/work/Delite-Clowler/node_modules/puppeteer/.local-chromium/linux-800071/chrome-linux/chrome ENOENT
TROUBLESHOOTING: https://github.com/puppeteer/puppeteer/blob/main/docs/troubleshooting.md
at onClose (/mnt/d/google drive/work/Delite-Clowler/node_modules/puppeteer/lib/cjs/puppeteer/node/BrowserRunner.js:193:20)
at ChildProcess.<anonymous> (/mnt/d/google drive/work/Delite-Clowler/node_modules/puppeteer/lib/cjs/puppeteer/node/BrowserRunner.js:185:85)
at ChildProcess.emit (events.js:223:5)
at Process.ChildProcess._handle.onexit (internal/child_process.js:270:12)
at onErrorNT (internal/child_process.js:456:16)
at processTicksAndRejections (internal/process/task_queues.js:81:21)
(node:14699) UnhandledPromiseRejectionWarning: Unhandled promise rejection. This error originated either by throwing inside of an async function without a catch block, or by rejecting a promise which was not handled with .catch(). (rejection id: 1)
(node:14699) [DEP0018] DeprecationWarning: Unhandled promise rejections are deprecated. In the future, promise rejections that are not handled will terminate the Node.js process with a non-zero exit code.
ページ取得に30秒以上かかると止まるらしい
try, exceptで囲うと良さそう
表題の平均文字数 = 平均10文字適度?
表題の容量 = 10*3byte = 30byte
輪郭数: 2,600,000
全輪郭の表題の容量 = 30*2600000byte = 78000000byte = 74.3865966796875MB
≪Headless Chrome Node.js API≫
https://github.com/puppeteer/puppeteer