RSS
2021/11/28 13:52:00
pnpm ng add @angular/ssrを実行してSSRを入れるif (isPlatformBrowser(this.platformId)) {で避けるようにはしたけどもっと良い方法がある気がするimport { Post } from "@/models";
import React from "react";
import { renderToString } from 'react-dom/server';
declare global {
namespace JSX {
interface IntrinsicElements {
[elemName: string]: unknown;
}
}
}
export function RssFeed({ posts }: { posts: Post[] }) {
return renderToString(
<rss version='2.0'>
<channel>
<language>ja</language>
<title>t_wの輪郭</title>
<rsslink>https://towasys.com/</rsslink>
<description>t_wの輪郭のRSSです。</description>
{posts.map(post => <item>
<title>{(post.title ? post.title : "あれ") + "|" + post.kno}</title>
<description>{post.body_html ?? ""}</description>
{post.posted_at && <pubDate>{new Date(post.posted_at * 1000).toUTCString()}</pubDate>}
<rsslink>{`https://towasys.com/${post.kno}`}</rsslink>
<guid isPermaLink="true">{`https://towasys.com/${post.kno}`}</guid>
</item>)}
</channel>
</rss>
).replaceAll("rsslink", "link")
}
getServerSidePropsで下記を実行
const rss_feed = RssFeed({ posts })
context.res.statusCode = 200
context.res.setHeader('Cache-Control', 's-maxage=86400, stale-while-revalidate') // 24時間キャッシュする
context.res.setHeader('Content-Type', 'text/xml')
context.res.end(rss_feed)
return {
props: {},
}
ノリと勢いで『t_wの輪郭』をReactで作り直しだウェーイってしてるけど、SEO死ぬんじゃねこれ
あとOGP対応無理くねコレ
何ならRSSも無理っぽい
AWS AmplifyでSSRする方法探すか
使用できますAWS Amplifyサーバー側レンダリング (SSR) を使用する Web アプリをデプロイしてホストします。現在、Amplify ホスティングは Next.js フレームワークを使用して作成されたアプリをサポートしています。
公式の日本語が怪しいけど、AWS AmplifyはNext.jsでSSR出来るらしい。
React+DataStoreからNext.jsに切り替えるぞッ!!!!
ここまで作ったフロントエンドを捨てることになるけど、メリットはあるし、やるしかねぇ。
NHK
ロイター
AFP
WIRED
ナショナルジオグラフィック
ナゾロジー
経済産業省
防衛省
JAXA
乗りものニュース
今までの検索サイトのビジネスモデルでは、検索サイトと検索によって表示されるサイト(以降「被検索サイト」と呼称)の間には互恵関係があった。検索サイトから個々のウェブサイトへ閲覧者が流入するという利点が被検索サイトにはあった。
LLMが検索サイトに搭載され、検索語で知りたい情報が検索サイト自身に表示されるのであれば、被検索サイトのページビューは減少する。
閲覧者の流入がないのであれば、被検索サイトにとって検索サイトが敵になる。クロールされ、負荷を強いられ、情報を搾取されるようになるからだ。今までは被検索サイトは得られる利益と引き換えに、こうした問題を受忍してきた。しかし利益がなければ受忍する道理はない。
故に、被検索サイトもAI絵師の問題と同様に、サイトからの情報を学習に利用されることを拒否するようになる。
そうして出てくるのは、LLMを搭載したブラウザやOSだ。利用者の手元でLLMが動作し、情報を収集し、利用者の問い合わせに応じて回答する。大規模言語モデルの小規模化もそれを後押しする。
利用者にとってはLLMを通して情報を取得する形となるが、検索サイトは仲介することによる利益を広告として得ることができなくなる。すなわち、情報流通の費用が低減するのだ。
続いて勃興するのはLLMに最適化された情報の提示だ。SEOが検索エンジンに最適化したように、LLMに最適化された情報を提示して、自身の事業に有利な出力をするように仕向ける。その形態はビジュアルである必要がないため、セマンティックウェブ的になる。
購読の意味合いも変わってきて、LLMに食わせる情報源として購読するという形態が発生する。RSSが形を変えて復興する。

プライバシー: ユーザーの行動や興味を反映させるためには、大量の個人データを収集する必要があります。これはプライバシーの問題を引き起こす可能性がある。
しかし、プライバシーの問題はむしろ霧散する。今のLLMは営利企業のサーバーによって実行されており、その際の問い合わせ内容はサーバーに保存される。しかし、各利用者の手元のOSで動作するLLMではその問い合わせ内容は外部に出ることはなく、完全にプライバシーが保護される。
個々のデバイスでAIの訓練を行うというのは、コンピューティングリソースの観点からも難しいかもしれない。
集約されたLLMと個人化されたLLMでは、サーバーで動作する「集約されたLLM」の方が潤沢なコンピューティングリソースを使うことができるため、相対的により“賢い”LLMを利用することができる。そのため、公共知は集約されたLLM、個人知は手元のOSで動作するLLM、のように使い分けることになる。
情報の正確さや信頼性を保証することが難しくなる。ユーザーが選択的に情報をクロールや購読する場合、情報源が偏ったり、誤った情報が混入する可能性がある。また、エコーチャンバーのような問題も生じる。
営利企業が運営するLLMに対しても同じことが言える。営利企業であるがために広告・宣伝・プロパガンダを混ぜ込むなどの意図的な偏りが発生する。
RSSのサイトURLが間違っているのを修正
RSSのdescriptionの説明文を修正すること ひとまず不要と判断。より良い説明文が思いついたら編集する。
RSSのサイトURLが間違っているのを修正すること DONE
RSSの配信を実装したもののまだ不具合がある。コンテンツを正しく表示できない。
また、試験体制にも問題がある。RSSリーダーのキャッシュによって、変更の確認が難しくなっている。
結局手動でSNSに共有と、RSSが有力か。
プッシュ通知を実装してもいいかもしれない。私自身は普段ウェブサイトのプッシュ通知を有効化しないが、有効化してくれる人がいれば強力な通知方法になる。
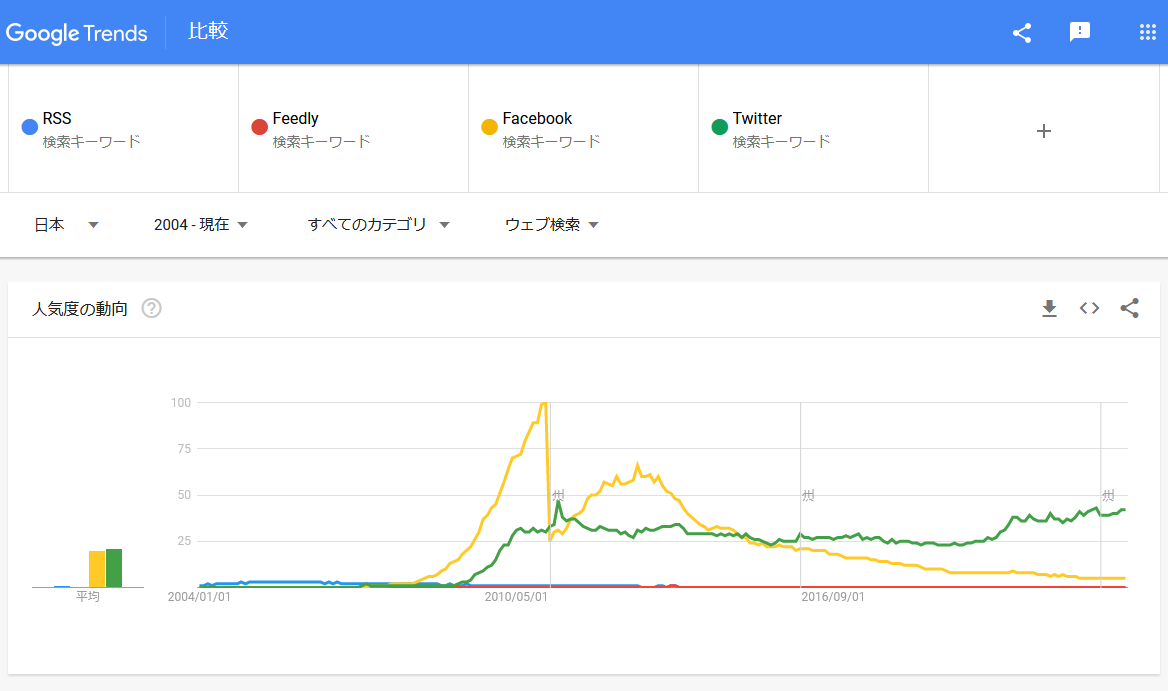
https://trends.google.co.jp/trends/explore?date=all&geo=JP&q=RSS,Feedly,Facebook,Twitter
RSSのサーバー側の実装が終わった後にGoogle Trendsで調べることに思い至った。
RSSとFeedlyを、TwitterやFacebookと比較すれば一目瞭然だ。やるべきはSNSからの流入を目的とした機能の実装だろう。
RSSリーダーの購読機能はSNSにざっくり代替された
これなんだよなぁ……
「RSS対応する暇あるならSNSに対応する」というのが合理的な態度というものなんだろう。
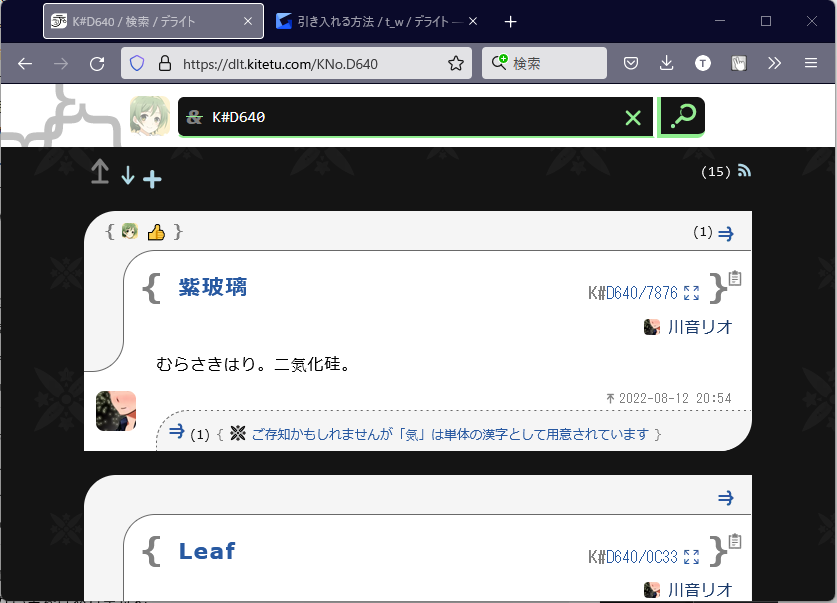
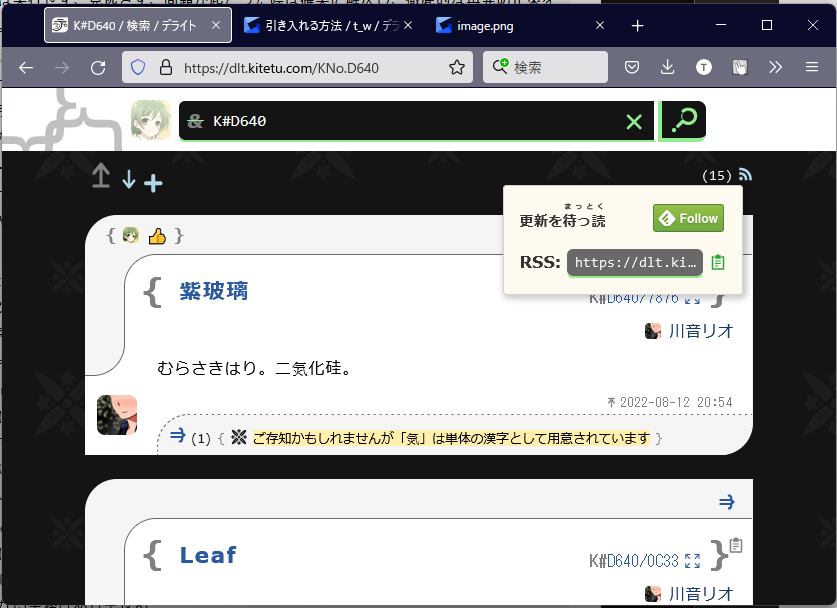
デライトのRSSを使えば、プログラムで輪郭を扱うことができて、本文がある輪郭の抽出ができるかと思ったがそうはいかなかった。10個までしか取得することができなかった。